9 – 10 – 11 – 12 -13 -14 stringhe e UNICODE
Una stringa è una sequenza di caratteri racchiusi tra due delimitatori, che possono essere i doppi apici o i singoli (esiste un terzo poco usato l’accento grave che viene usato per delimitare una stringa su più righe).
var s1 = "sono una stringa"; var s2 = 'sono una stringa'; var s3 = `sono una striunga`;
le 3 variabili hanno tutte lo stesso valore. Fare attenzione che copiando il codice possono essere copiate le virgolette verticali che non vengono accettate come stringhe.
I caratteri nella ram del computer sono rappresentate come sequenze di bit (in unità di 8 bits indivisibili cioè i bytes), che interpretati in un certo modo possono rappresentare interi o floating point, seguendo un altro schema, invece, anche dei caratteri. La distinzione di questi bits è la codifica che è rappresentata nella tabella ASCII dove i numeri sono associati a dei caratteri. Ogni carattere (anche lo spazio, gli operatori, i null….) occupano spazio in memoria. Esistono altre codifiche oltre a quella ASCII (che ha solo 127 caratteri) come la EBCDIC per i grossi sistemi o la ASCII estesa che porta il numero di codici a 256.
La situazione creatasi era che molti paesi avevano una loro tabella:
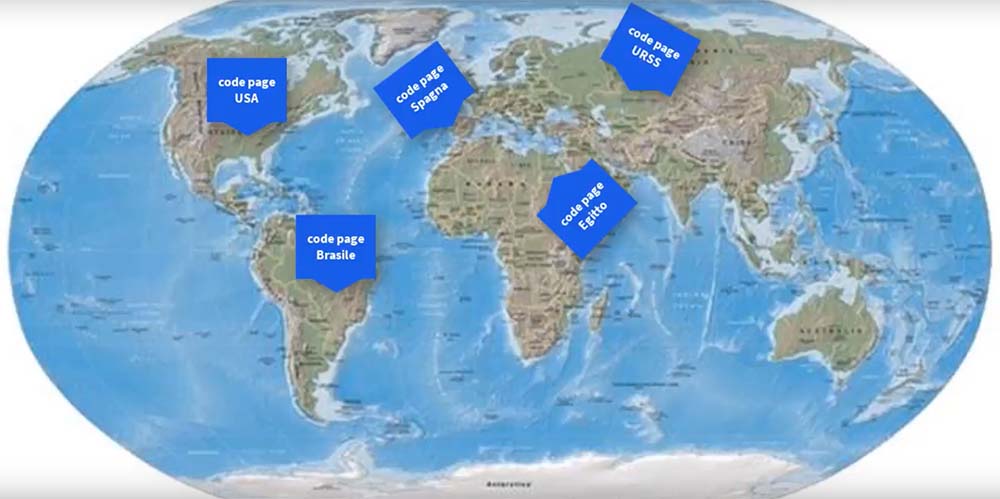
Dove i primi 127 caratteri erano identici indipendentemente dalla nazione, ma oltre il centoventisettesimo potevano essere completamente diversi con significati profondamente diversi creando grandi fraintendimenti. Nelle codifiche orientali per esempio 1 byte non era sufficiente a contenere gli ideogrammi, oppure come avrebbe potuto un russo scrivere in russo un trattato sulla lingua svedese con caratteri completamente diversi? visto che non si può usare nello stesso documento codifiche differenti.
Con la globalizzazione dell’informatica si è passati ad uno standard che potesse rappresentare tutti i caratteri: l’ UNICODE . Per spiegare l’UNICODE, innanzitutto bisogna staccarsi dal concetto di carattere legato ad un codice numerico. Pensiamolo come ad una enorme tabella, formata da point, che contiene TUTTI i caratteri esistenti chiamati code point .
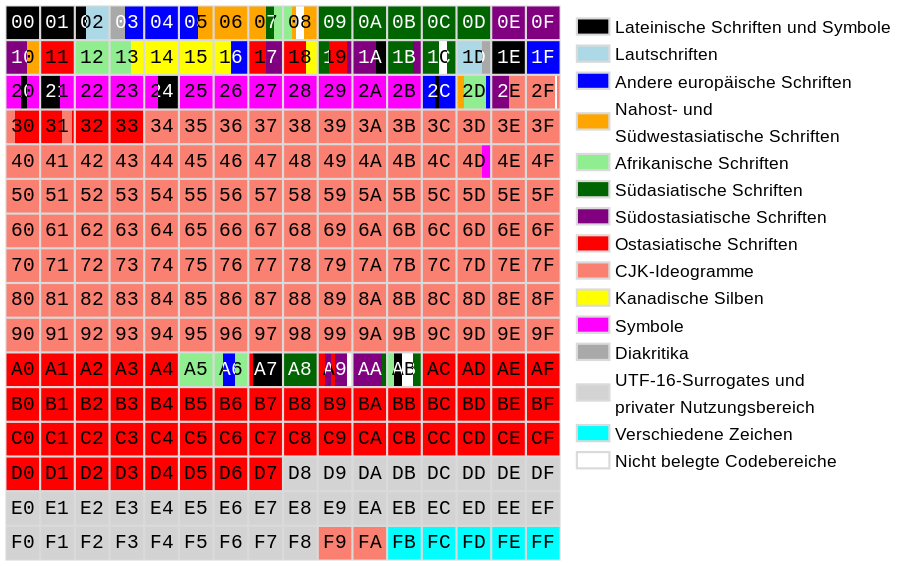
Ogni quadratino della tabella rappresenta un insieme di 256 code point (caratteri). Si è deciso di privilegiare i point contenenti i caratteri occidentali e trovano posto nelle prime posizioni (quadrato 00 – 01 – 02) e così via per tutta la figura. Il quadrato totale di tutta la figura (l’insieme dei quadratini colorati), forma 1 dei 17 plane esistenti. Quello visto in figura viene chiamato Basic Multilingual Plane o BMP o piano zero. Il secondo è il Supplementary Multilingual Plane, poi l’Idegraphic e così via fino al 17°.
Veniamo ai conti: ogni point (quadratino) contiene 256 code point (caratteri o simboli). Ogni plane contiene 16 x 16 blocchi da 256 cadauno, per un totale di 256 al quadrato che fa 65,536 che moltiplicato per i 17 plane fa 1.114.112 code point, anche se molti sono ancora vuoti.
Le coordinate binarie di qualunque codepoint sono rappresentate da 6 cifre esadecimali ( es: hhhhhh ) , di cui le prime 2 ( es: hhhhhh ) identificano il plane di cui però avendone solo 17 si partirà dal primo 00 al diciassettesimo che in esadecimale si rappresenta con 10 . Le altre 4 cifre esadecimale servono tutte quindi il range sarà da 000000 a 101111.
Ogni cifra esadecimale necessita di 4 bit, quindi con un byte posso rappresentare 2 cifre, per cui per rappresentare tutto il codice esadecimale di 6 cifre impegnerò 3 byte, usandoli dovremmo poter rappresentare qualsiasi codice dell’unicode, ma la realtà invece è diversa, 3 byte non è un numero perfetto per le rappresentazioni binarie, ma soprattuto per vari aspetti architetturali a livello di microprocessore, dovremo confrontarci con l’encoding dei caratteri.
L’encoding è un modo ottimizzato per far corrispondere una sequenza di bits nelle ram dei computers ad un certo code point. Infatti tramite l’encoding dell’unicode si possono usare codifiche a 32 bit come la Unicode Transormation Format o UTF-32. Vi sono altri comuni chiamati codifiche a lunghezza variabile, che si basa sul concetto di usare meno byte per rappresentare i caratteri più frequenti, impegnando maggiori risorse per quelli usati raramente. Per esempio UTF-8 che utilizzerà 1 solo byte per rappresentare i caratteri ASCII degli Stati Uniti (utilizzati di frequente) mentre ne impegna di più di quelli necessari per gli altri caratteri fuori dall’ASCII, con spreco di risorse e sarebbe magari consigliabile usare un’altra codifica:

Nell’esempio in figura si vede la differenza di uso di byte per rappresentare la lettera A nei vari encoding: UTF-8 -> 1 byte , UTF-16 -> 2 byte , UTF-32 -> 4 byte . L’altro carattere invece UTF-8 -> 3 byte , UTF-8 -> 2 byte , UTF-8 -> 4 byte, in questo caso l’UTF-16 risparmia 1 byte per 1 solo carattere.
Curiosità :
Lo spazio dei code point UNICODE è talmente ampio che larghe porzioni sono concesse ad uso privato per scopi non proprio professionali. C’è chi ha pensato di inserire caratteri di un alfabeto completamente immaginario come l’alfabeto extraterrestre Klingon !
I siti di buon livello, normalmente non trascurano nel loro head la specifica meta dell’encoding
<meta charset="UTF-8" /> <meta content="text/html; charset=utf-8" http-equiv="Content-Type" />
Senza queste specifiche i browser devono andare ad indovinare la codifica utilizzata, con conseguenze disastrose di eventuali caratteri inopportuni.
Per avere una lista dei caratteri o simboli presenti nell’UNICODE, si può visualizzare Wikipedia , o siti specifici aggiornati, oppure vediamo come js interpreta l’UNICODE
var stringa1 = "ciao"; console.log(stringa1 + ": " + stringa1.length);
stampo nella console il valore della stringa1 , concatenato ( segno di concatenamento di più stampe +) ai due punti, concatenato alla lunghezza della stringa1, risultato: ciao: 4.
La lunghezza della variabile stringa in realtà in js è un oggetto e come tale ha dei comandi o delle proprietà. La proprietà lenght mi restituisce la lunghezza del valore di stringa1.
Quando ci si scambiano dati è sempre utile indicare il tipo di codifica, js di default utilizza la codifica UTF-16.
Vediamo un esempio l’ escape \ che permette di comunicare a js che da quel momento si inserisce una codifica speciale e sfuggire dal normale flusso :
var stringa1 = "ciao\n\n\nciao"; console.log(stringa1 + ": " + stringa1.length);
Ottengo ciao seguito da 3 spazi (\n vuol dire interrompi la stringa e stampa 3 new line), un altro ciao e una lunghezza del valore di 11 (per \n utf-16 utilizza 1 carattere).
Ecco le sequenze di escape:
- \n new line
- \t tab
- \b backspace
- \r carriage return
- \\ backslash
- \’ single quote
- \” double quote
- \u UNICODE
La sequenza di escape permette di esprimere caratteri particolari UNICODE. Vado sulla mappa dei codici, cedo il carattere che mi interessa e prendo il suo codice U+ corrispondente. Per esempio ho scelto (a caso) il plane BMP, la tabella 9000-9FFF, il code point 9070
var stringa2 = "\u{9070}";
console.log(stringa2 + ": " + stringa2.length);
che corrisponde al valore: 遰: 1 (probabilmente ideogramma cinese), che comunque vale 1 in UTF-16.
Per rappresentare un carattere al di fuori del BMP e che quindi in UTF-16 occuperebbe 2 bit, con il vecchio ecmascript 5 avrei dovuto utilizzare le surrogate pairs , la coppia dei 2 codici corrispondenti al simbolo. Con ecmascript 6 invece è possibile specificare direttamente il codice
var stringa3 = "\u{1F680}";
console.log(stringa3 + ": " + stringa1.length);
Che corrisponde ad un razzetto che occupa 2 byte : ?: 2 (plane 1 blocco che mostra i caratteri che vanno da 1F000 a 1FFFF area trasporti e simboli per le mappe).
Questo carattere essendo formato da 1 coppia di 2 valori numerici memorizza i 2 valori in stringa3, inizializzando stringa3 come array. Esiste una funzione che restituisce i valori numerici di un carattere che charCodeAt seguita dal suo indice
var stringa3 = "\u{1F680}";
console.log(stringa3.charCodeAt(0), stringa3.charCodeAt(1));
charCodeAt(0) restituisce 55357, charCodeAt(1) restituisce 56960 che insieme formano il razzetto.
La funzione si può usare anche su una stringa normale:
console.log("ciao".charCodeAt(0), "ciao".charCodeAt(1));
restituiscimi il codice numerico (il vecchio ASCII in questo caso) della posizione 0 che corrisponde alla lettera c che corrisponde al codice 99 e restituiscimi il codice numerico della posizione 1 che corrisponde alla lettera i che corrisponde al codice 105.
Se vogliamo invece il code point di un carattere, ci viene comoda la funzione codePointAt, senza andare tutte le volte su Wikipedia ?
var test = "?"; console.log(test.charCodeAt(0));
che restituisce il valore 127863 che corrisponde al codice esadecimale 1F377.
Si può usare anche l’escape combinato anche sul nome di una variabile (perversione) :
var annat\u{41} = 2017;
console.log(annatA);
o tutto il nome in UNICODE
var \u{1f68} = 2017;
console.log("\u{1f68}");
ecco creata la variabile Ὠ (omega).